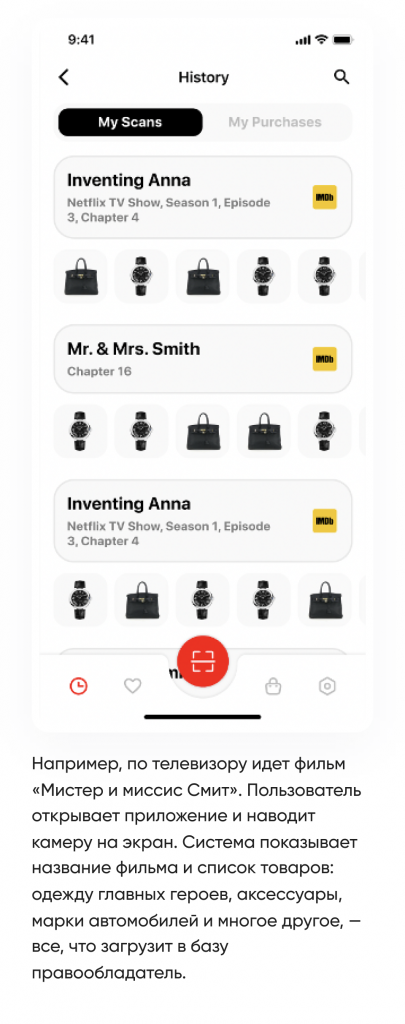
Задача
Этапы разработки
1. Распознавание монитора
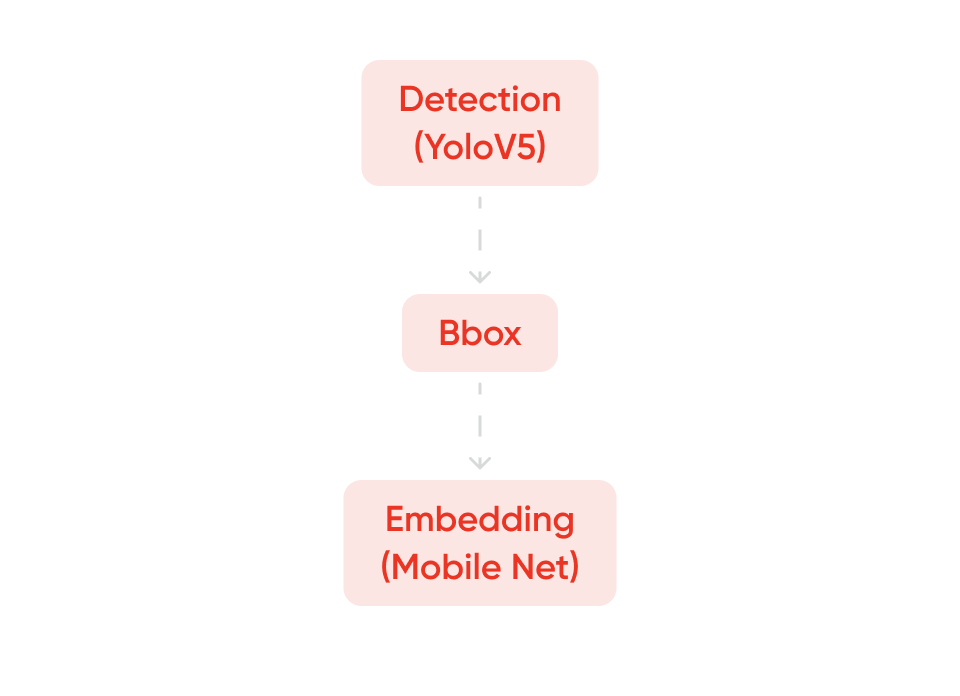
2. Превращение кадра в числовый вектор — эмбеддинг
3. Работа с базой
4. Создание списка товаров
Это уникальный проект с точки зрения машинного обучения. Здесь было важно сделать не только решение с высоким качеством распознавания, но и оптимизировать его для исполнения в реальном времени на мобильном устройстве. Вместе с командой Amiga мы портировали пайплайн распознавания на Dart и получили решение, которое отлично работает в реальном времени на широком спектре мобильных устройств и на iOS, и на Android.

Андрей Татаринов
СEO AGIMA.AI
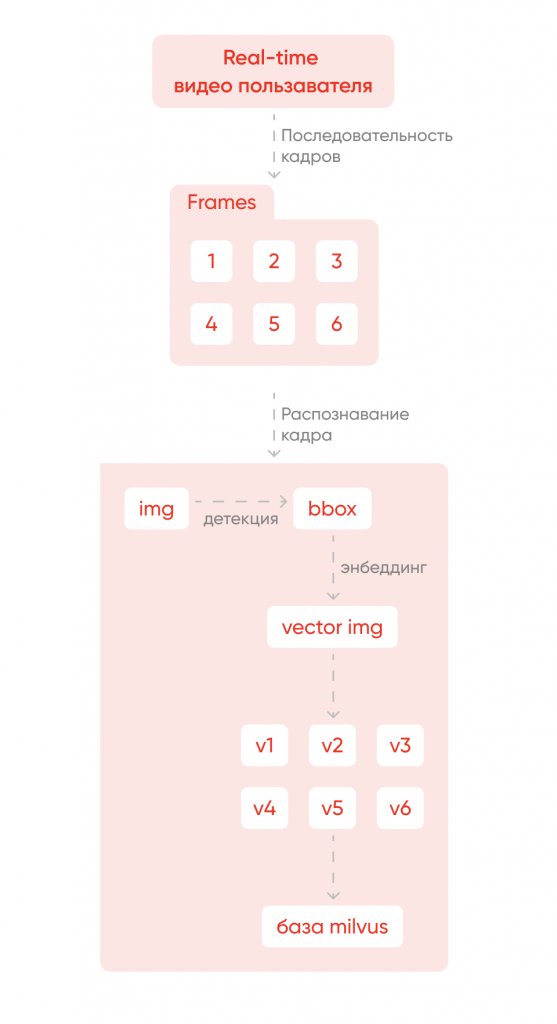
Как устроено распознавание видео
Числовые векторы-кадры из видео пользователя сопоставляются с векторами-кадрами из базы Milvus. Посредством голосования большинством определяются ближайшее похожее видео из базы, а также конкретный сегмент видео.
Автоматическое обновление базы видео
Сервис отслеживает изменения в облачной базе данных. Если в базе появляется новое видео — название и ссылка на файл, то сервис автоматически скачивает его, кадрирует, присваивает числовые векторы и загружает векторы в Milvus. После этого пользователь сможет найти это видео с помощью приложения.

Анна Закутняя
ML-Engineer AGIMA.AI
Как создаются списки товаров
В итоге получается такая схема:

Технологии
- Детектор — YOLOv5.
- Эмбедер — MobileNet, обученный на картинах с использованием слоя ArcFace.
- Таблицы c информацией по видео и товарам — Grist.
- Точность распознавания видео — 96%.
- ML-сервис Datapipe для обновления базы Milvus.
- Фреймворк для мобильного приложения — Flutter.
Команда Amiga за короткие сроки сделала большую работу. Хочется отметить, что Amiga и AGIMA.AI в синергии заточены под быстрый запуск MVP-версий. Заказчик получил полностью работающее мобильное приложение, в планах развивать его и дальше.

Дмитрий Тарасов
CEO Amiga
Результат
- Построили ML-модель, которая умеет распознавать 150 фильмов и товары в кадре. Базу фильмов можно автоматически пополнять.
- Видео пользователя кадрируется со скоростью 1 кадр в 200 мс в режиме realtime.
- Фильм и товары распознаются за 2,4 секунды в режиме realtime.
- Точность распознавания видео — 96%.
Над проектом работали
-
Анна Закутняя
ML-Engineer
-
Андрей Татаринов
CEO AGIMA.AI
-
Александр Козлов
Machine Learning Developer AGIMA.AI
-
Дмитрий Тарасов
CEO Amiga


